
OpenAI با معرفی جیپیتی 5، استاندارد جدیدی برای مدلهای زبانی مولد و سامانههای هوش مصنوعی چندوجهی وضع کرده است. این نسل تازه، نهتنها در آزمونها و بنچمارکهای معتبر رکوردهای تازهای ثبت کرده، بلکه در تجربه واقعی کاربران نیز ملموستر و کارآمدتر از نسلهای پیشین ظاهر میشود. GPT‑5 بر یک معماری یکپارچه بنا شده که میداند چه زمانی باید سریع پاسخ بدهد و چه زمان بهتر است ژرفتر و طولانیتر بیندیشد تا پاسخی در سطح کارشناس ارائه کند. این مدل اکنون برای تمام کاربران ChatGPT در دسترس است؛ مشترکان Plus از سهمیه استفاده بالاتر بهره میبرند و مشترکان Pro به نسخه GPT‑5 Pro با استدلال توسعهیافته و دقت بیشتر دسترسی دارند.
یک سامانه یکپارچه که باهوش تصمیم میگیرد
GPT‑5 یک اکوسیستم یکپارچه متشکل از چند مؤلفه کلیدی است: یک مدل اصلی سریع و بهینه برای پاسخ به اغلب پرسشها، یک مدل استدلال عمیق با نام GPT‑5 Thinking برای مسائل سخت و پیچیده، و یک روتر بلادرنگ که با توجه به نوع گفتگو، میزان پیچیدگی، نیاز به ابزارها و نیت صریح شما بهصورت خودکار تصمیم میگیرد کدام مسیر را فعال کند. اگر در ابتدای پیام تأکید کنید «روی این موضوع عمیق فکر کن»، مدل متوجه میشود که باید حالت استدلال توسعهیافته را فعال کند.
این روتر بهصورت پیوسته با سیگنالهای واقعی آموزش میبیند: از تغییر مدلها توسط کاربران گرفته تا نرخ ترجیح پاسخها و شاخصهای سنجش درستی. نتیجه اینکه هرچه میگذرد، انتخابهای آن دقیقتر و سازگارتر با بافت مکالمه میشود. وقتی به سقف استفاده روزانه برسید، نسخههای «مینی» از هر مدل، پاسخگویی به درخواستهای باقیمانده را بهصورت چابک ادامه میدهند. طبق برنامه OpenAI، این قابلیتها بهزودی در قالب یک مدل واحد ادغام میشوند تا هم تجربه کاربری یکدستتر شود و هم سربار تصمیمگیری کاهش یابد.
جیپیتی 5 دقیقتر، سریعتر و مفیدتر برای مسائل دنیای واقعی
یکی از برجستگیهای GPT‑5، عبور از مرز صرفاً «بهتر بودن در بنچمارکها» و نزدیک شدن به نیازهای واقعی است. OpenAI در این نسل روی سه محور پرکاربرد ChatGPT تمرکز ویژه داشته است: نوشتن و تولید محتوا، کدنویسی و پرسشهای مرتبط با سلامت. در عین حال، نرخ «خیالپردازی» یا تولید خطای واقعی (Hallucination) کاهش محسوسی یافته، پیروی از دستورالعملها دقیقتر شده و رفتار «تملقگویی» (Sycophancy) به شکل معناداری کم شده است.
نوشتن و خلاقیت؛ همکار نویسندهای که ریتم و ساختار را میفهمد
GPT‑5 در نقش شریک نویسندگی، بیش از هر نسل دیگری توانمند و قابل اتکا است. از گرفتن ایدههای خام و سازمان دادن آنها گرفته تا نگارش متنهایی با عمق، ریتم و ضرباهنگ ادبی، این مدل درک بهتری از فرم و محتوا نشان میدهد. متونی که ساختار مبهم یا «فرم آزاد» دارند، بهتر از قبل پردازش میشوند؛ از جمله تداوم یک وزن مشخص بیقافیه یا خلق نثر آزاد که بهصورت طبیعی جریان پیدا میکند. نتیجه برای کارهای روزمره ملموس است: تهیه و ویرایش گزارشها، ایمیلها، یادداشتهای سازمانی و حتی نگارشهای بازاریابی با وضوح، انسجام و سبک مناسب. در کنار این، بهروزرسانیهای اخیر باعث شده خروجی جیپیتی 5 از نظر لحن، کمتر «ماشینی» و بیشتر شبیه یک همکار انسانی آگاه و دقیق احساس شود.
کدنویسی؛ از فرانتاند پیچیده تا باگیابی مخازن بزرگ
در حوزه توسعه نرمافزار، GPT‑5 قویترین مدل کدنویسی OpenAI تا امروز است. در تولید فرانتاندهای پیچیده، تکمیل رابطهای کاربری واکنشگرا، و دیباگ مخازن بزرگ نرمافزاری پیشرفت چشمگیری مشاهده میشود. بسیاری از آزمایشکنندگان اولیه گزارش دادهاند که جیپیتی 5 با یک پرامپت مناسب میتواند یک وبسایت، اپلیکیشن یا حتی یک بازی را با سلیقه بصری قابلقبول بسازد؛ از فاصلهگذاری و تایپوگرافی گرفته تا استفاده بهجا از فضای سفید، درک زیباییشناختی بهتری پیدا کرده است. برای توسعهدهندگان، این به معنای سرعت بیشتر در پروتوتایپینگ و کیفیت بالاتر در خروجی UI/UX است. افزون بر این، پشتیبانی روانتر از جریانهای کاری چندابزاره و «agentic coding» (کدنویسی عاملی) سبب میشود وظایف چندمرحلهای پیچیده را از ابتدا تا انتها بهصورت خودکار و هماهنگ پیش ببرد.
سلامت دیجیتال؛ پاسخهای دقیقتر، همدلانهتر و با احتیاط حرفهای
در پرسشهای مرتبط با سلامت، GPT‑5 بهترین عملکرد را میان مدلهای OpenAI نشان داده است. در ارزیابی HealthBench که بر اساس سناریوهای واقعی و معیارهای تعریفشده توسط پزشکان طراحی شده، GPT‑5 به شکل محسوسی از نسلهای قبلی بهتر ظاهر میشود. نکته مهم اینکه مدل بیشتر شبیه یک همفکر فعال عمل میکند: نگرانیهای بالقوه را بهصورت پیشدستانه مطرح میکند، پرسشهای روشنکننده میپرسد و پاسخهایی مطابق با سطح دانش، بافت فرهنگی-جغرافیایی و نیازهای هر کاربر ارائه میدهد. با این حال، ChatGPT جایگزین تخصص پزشکی نیست؛ بهتر است آن را یک همراه برای فهم نتایج آزمایشها، طرح پرسشهای بهتر در زمان محدود و سبکسنگین کردن گزینهها در تصمیمگیریهای سلامت در نظر بگیرید.
بنچمارکها و ارزیابیها؛ رکوردشکنی در ریاضی، کدنویسی، بینایی و سلامت
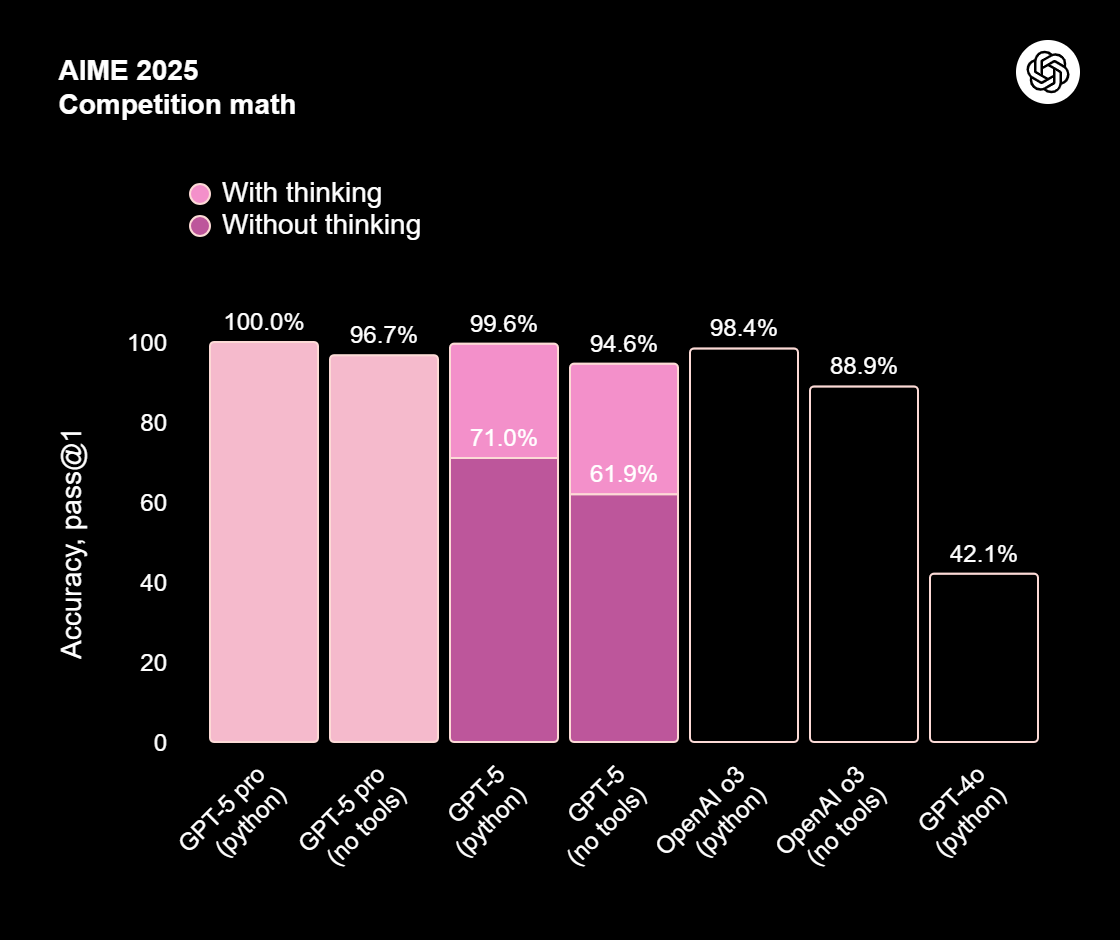
عملکرد GPT‑5 در طیف گستردهای از بنچمارکهای آکادمیک و انسانی ارزیابی شده و جهشی سراسری را نشان میدهد، بهویژه در ریاضیات، کدنویسی، ادراک بصری و سلامت. در ریاضی، بدون استفاده از ابزار، امتیاز 94.6% در آزمون AIME 2025 ثبت شده است. در کدنویسی دنیای واقعی، نتایج 74.9% روی SWE‑bench Verified و 88% روی Aider Polyglot بهدست آمده است. همچنین در فهم چندوجهی (Multimodal) امتیاز 84.2% روی MMMU و در بخش دشوار سلامت (HealthBench Hard) امتیاز 46.2% گزارش شده است. این اعداد صرفاً دستاوردهای آزمایشگاهی نیستند؛ کاربران در کار روزمره نیز از دقت و ثبات بیشتر بهرهمند میشوند.
نسخه جیپیتی 5 پرو که استدلال عمیقتری دارد، در GPQA—یکی از چالشبرانگیزترین مجموعهسؤالات علمی—به رکورد جدیدی رسیده و بدون بهرهگیری از ابزار به امتیاز 88.4% دست یافته است. این دستاوردها نشان میدهند معماری جدید و روشهای آموزش تازه، درک و استدلال را به سطح تازهای ارتقا دادهاند.
پیروی بهتر از دستورالعملها و استفاده عاملی از ابزارها
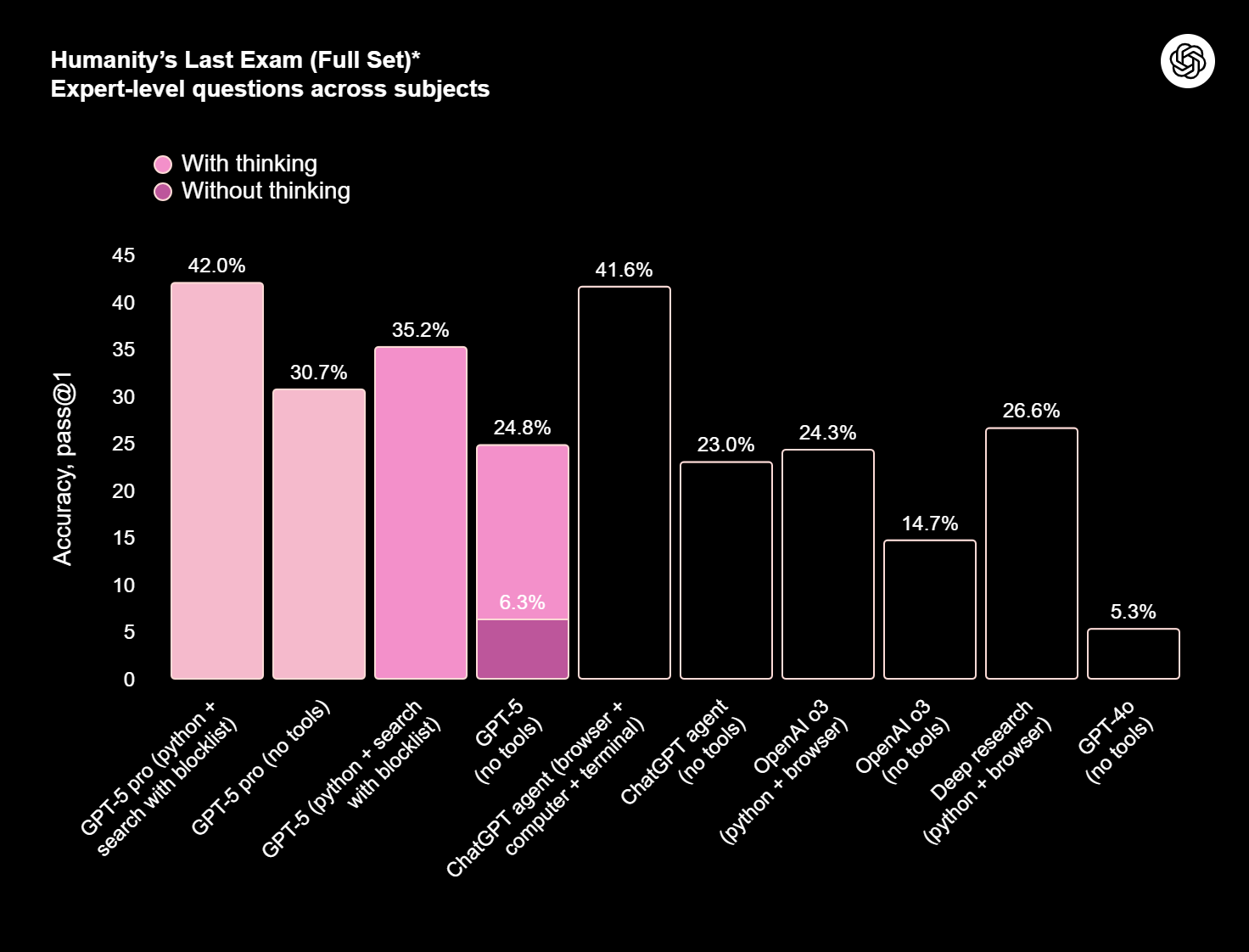
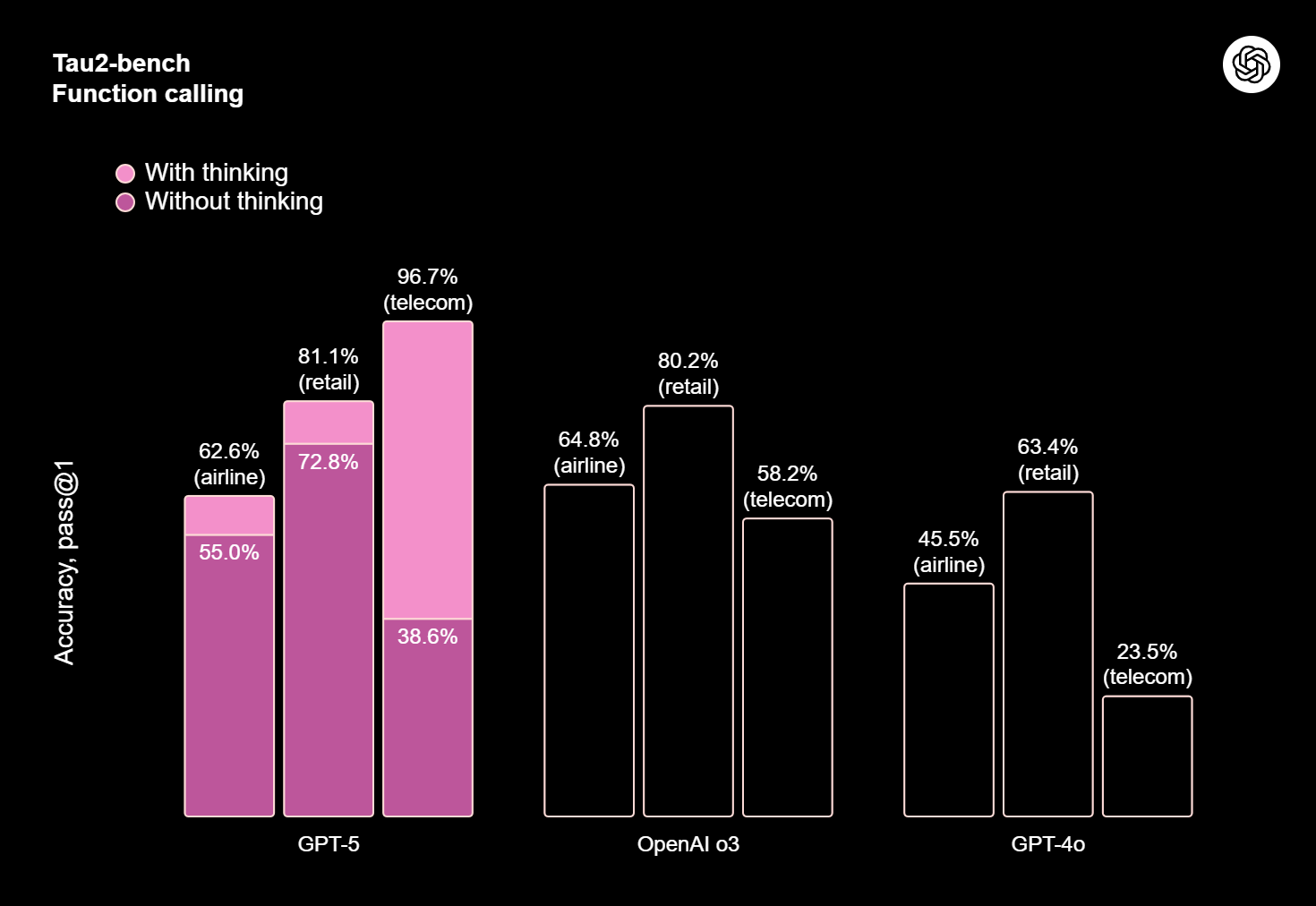
جیپیتی 5 در آزمونهایی که توانایی تبعیت از دستورالعملها، انجام کارهای چندمرحلهای و هماهنگی بین ابزارها را میسنجند، جهش قابلتوجهی داشته است. در عمل، این یعنی وقتی از آن میخواهید میان چند سرویس جابجا شود، دادههایی را از یک منبع بیرونی بگیرد، خلاصه کند و بعد خروجی را در قالبی دقیق تحویل دهد، کمتر به تذکر مجدد یا اصلاح دستی نیاز دارید. علاوه بر این، توانایی مدل برای وفقپذیری با تغییر زمینه مسئله—مثلاً وقتی ورودیها تغییر میکنند یا ابزار مدنظر در دسترس نیست—بهبود یافته و نرخ موفقیت انجام «انتها به انتها»ی وظایف بیشتر شده است.
توانایی چندوجهی؛ از تصویر تا ویدئو و استدلال علمی
در آزمونهای چندوجهی که شامل تحلیل بصری، ویدئویی، استدلال فضایی و علمی هستند، GPT‑5 بالاتر از نسلهای پیشین ظاهر شده است. نتیجه عملی این پیشرفت، توانایی بهتر در تفسیر نمودارها، خلاصهسازی اسلایدهای ارائه، پاسخ به سؤالات درباره دیاگرامها و حتی بررسی عناصر تصویری پیچیده است. به همین دلیل، برای تیمهای داده، پژوهشگران، طراحان محصول و حتی مدیران غیرفنی که باید ارائههای تصویری را سریع مرور کنند، GPT‑5 ابزار قابلاعتمادتری است.
کارهای اقتصادی با ارزش افزوده بالا
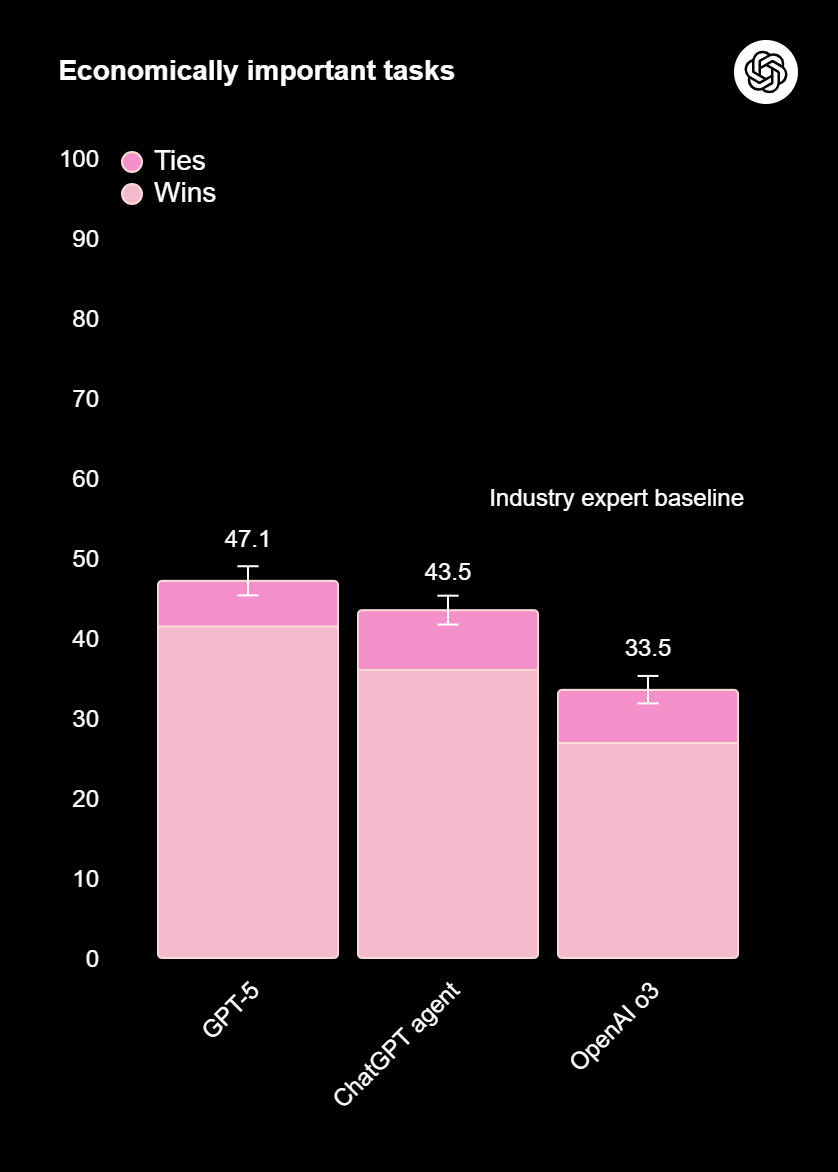
OpenAI یک بنچمارک داخلی برای سنجش توانایی مدلها در «دانشکاری پیچیده و ارزشمند اقتصادی» دارد. GPT‑5 در این ارزیابیها نیز بهترین عملکرد را تا امروز نشان داده است. در سناریوهایی که نیازمند استدلال گامبهگام هستند، جیپیتی 5 در حدود نیمی از موارد با متخصصان باتجربه برابری میکند یا بهتر است، و در حوزههای مختلفی از جمله حقوق، لجستیک، فروش و مهندسی از مدلهای o3 و ChatGPT Agent برتری داشته است. برای شرکتها، این یعنی بازدهی بالاتر، اتوماسیون مطمئنتر و کاهش نیاز به بازبینی دستی در پروژههای پیچیده.
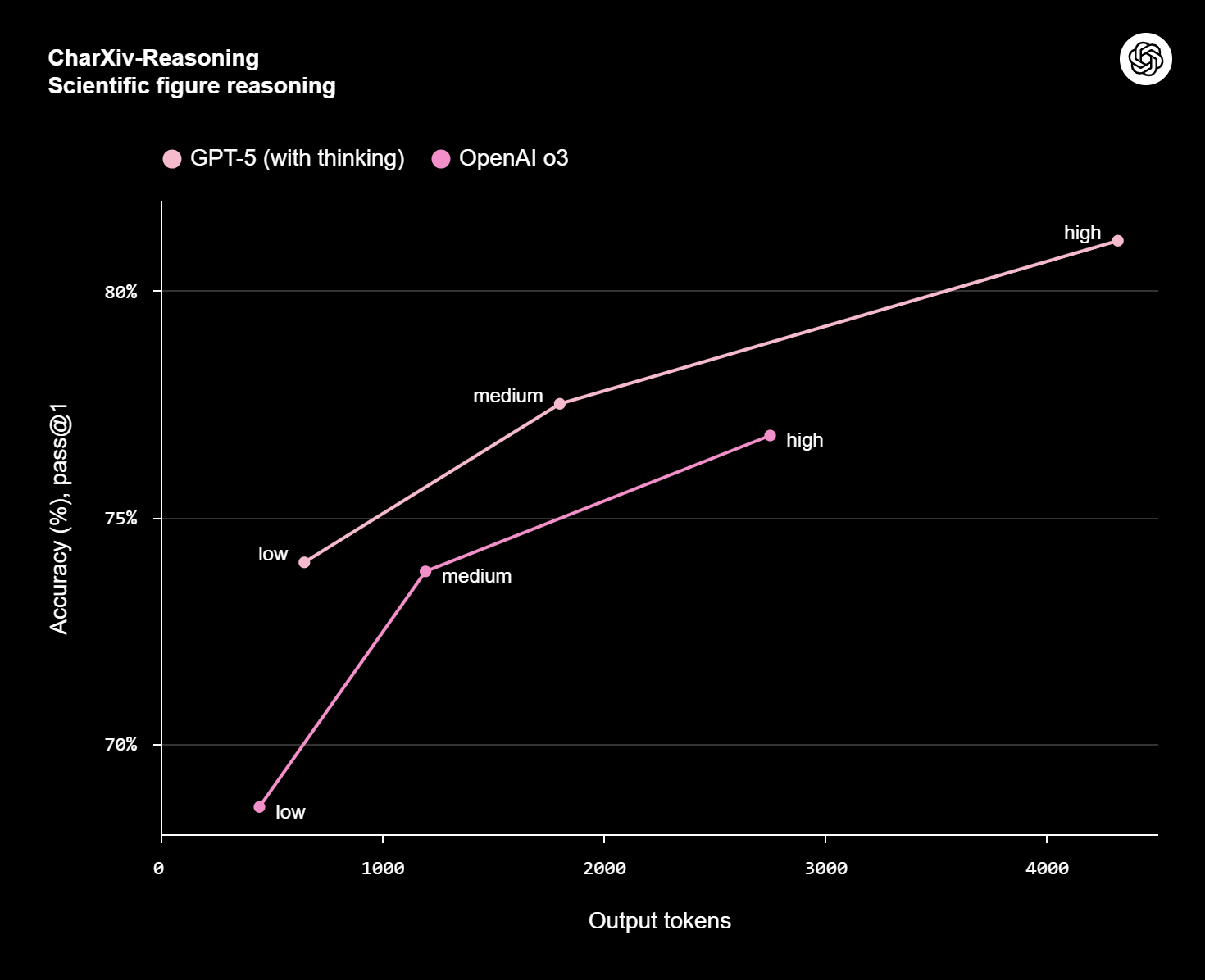
تفکر سریعتر و کارآمدتر؛ کیفیت بیشتر با توکن کمتر
در ارزیابیهای داخلی، GPT‑5 (در حالت Thinking) با 50 تا 80 درصد توکن خروجی کمتر نسبت به OpenAI o3، نتایج بهتری ارائه کرده است—آن هم در تواناییهای متنوعی مانند استدلال بصری، کدنویسی عاملی و حل مسائل علمی در سطح کارشناسی ارشد. به زبان ساده، GPT‑5 در زمان کمتر، محتوای باکیفیتتری تولید میکند و هزینه محاسباتی را هم پایینتر نگه میدارد.
مدلی دقیق، قابلاعتماد و یاریرسانتر
کاهش محسوس خیالپردازی در پرسشهای واقعی
یکی از چالشهای قدیمی مدلهای زبانی، تولید اطلاعات نادرست با اعتمادبهنفس است. با فعال بودن جستوجوی وب روی پرامپتهای بینام و نماینده ترافیک واقعی ChatGPT، پاسخهای جیپیتی 5 حدود 45% کمتر از GPT‑4o حاوی خطای factual هستند. در حالت Thinking، این کاهش نسبت به OpenAI o3 تا حدود 80% میرسد.
برای فشارسنجی دقیقتر روی سؤالات باز و حقیقتمحور، تیم OpenAI ارزیابیهای جدیدی را اضافه کرده است. در دو بنچمارک عمومی LongFact (برای مفاهیم و اشیا) و FActScore، «GPT‑5 Thinking» جهش بزرگی نشان میدهد؛ نرخ خیالپردازی حدود 6 برابر کمتر از o3 گزارش شده است. این پیشرفت، تولید محتوای بلند و پیوسته را بهصورت پایدارتر و دقیقتر ممکن میکند.
صداقت بیشتر در بیان تواناییها و محدودیتها
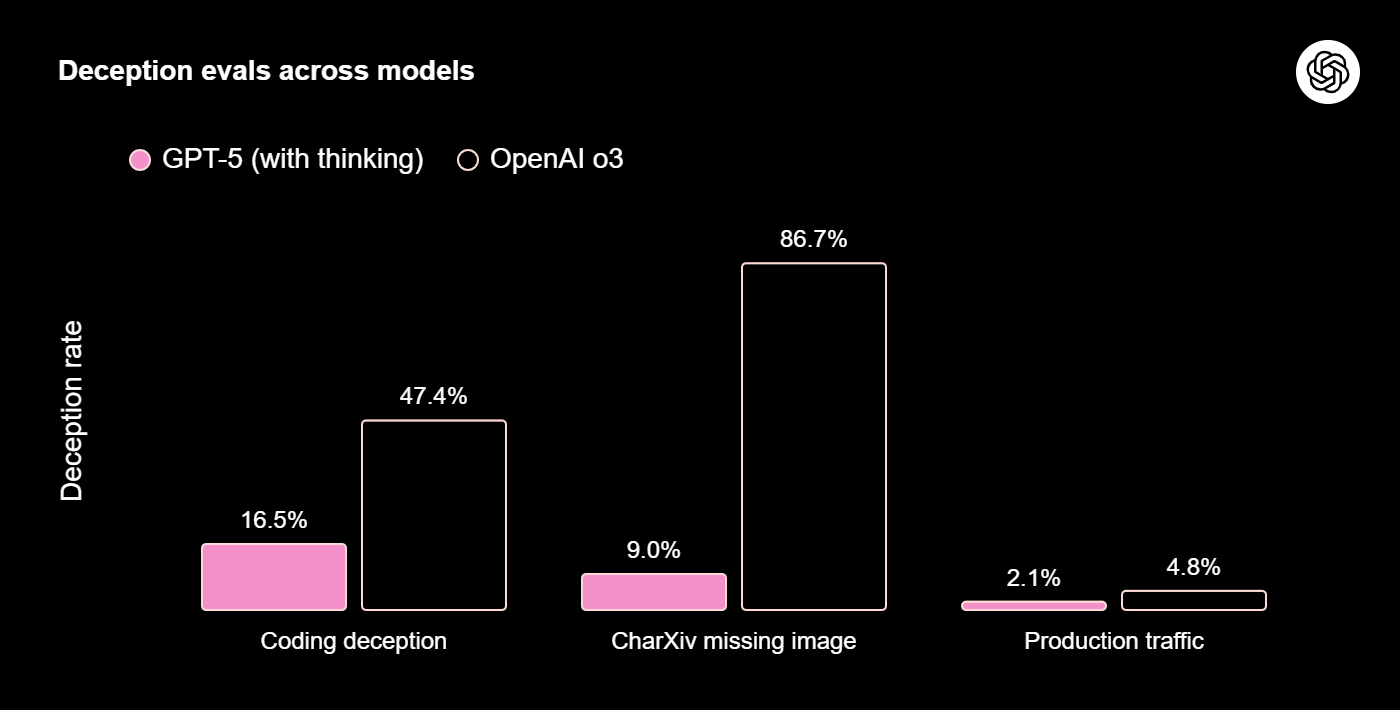
افزون بر بهبود واقعنمایی، GPT‑5 (در حالت Thinking) شفافیت بیشتری در مورد کارهایی که قادر به انجامشان است یا نیست دارد—بهویژه وقتی مسئله «ناممکن»، «مبهم» یا «نیازمند ابزاری خارج از دسترس» باشد. در آزمون CharXiv، تصاویر از ورودی حذف شد تا مدلها فریب بخورند؛ نتیجه نشان داد OpenAI o3 در 86.7% موارد درباره تصاویر وجودنداشته با اعتمادبهنفس پاسخ میدهد؛ در حالیکه برای GPT‑5 این رقم به حدود 9% کاهش یافته است.
در سناریوهای کدنویسی ناممکن یا فقدان اجزای چندوجهی، نرخ فریبکاری (Deception) GPT‑5 در حالت Thinking نسبت به o3 کمتر است. روی مجموعه بزرگی از گفتگوهای واقعی، نرخ فریبکاری از 4.8% (در o3) به 2.1% در پاسخهای استدلالی GPT‑5 کاهش یافته است. هرچند این پیشرفت معنادار است، اما OpenAI همچنان روی بهبود واقعنمایی و صداقت مدلها پژوهش میکند.
ایمنی هوشمندتر: از «امتناع» تا «تکمیل ایمن»
تا پیش از این، آموزشهای ایمنی ChatGPT غالباً بر امتناع یا پاسخگویی کامل مبتنی بود. این رویکرد برای پرامپتهای صراحتاً مخرب خوب کار میکند، اما در نیتهای مبهم یا حوزههای دوسویه (Dual‑Use) مثل ویروسشناسی که پاسخ سطحبالا بیخطر است اما جزئیات میتواند خطرناک باشد، انعطاف کافی ندارد.
GPT‑5 رویکردی جدید معرفی میکند: «Safe Completions» یا تکمیل ایمن. این پارادایم به مدل میآموزد تا در چهارچوبهای ایمنی، مفیدترین پاسخ را ارائه کند؛ گاهی یعنی پاسخ بخشی از سؤال را بدهد یا صرفاً در سطح بالا توضیح دهد. اگر نیاز به امتناع باشد، مدل روشن توضیح میدهد چرا و چه جایگزینهای امنی وجود دارد. آزمایشهای کنترلشده و نسخههای عملیاتی نشان دادهاند این روش، پیمایش پرسشهای دوسویه را هوشمندانهتر میکند، در برابر نیتهای مبهم مقاومتر است و از امتناعهای غیرضروری میکاهد.
کاهش تملقگویی و پالایش لحن گفتگو
در مقایسه با GPT‑4o، مدل جدید کمتر خوشآمدگوی افراطی است، از ایموجیهای غیرضروری کمتر استفاده میکند و پیگیریهای بعدی (Follow‑ups) را دقیقتر و سنجیدهتر انجام میدهد. چندی پیش بهروزرسانیای در GPT‑4o ناخواسته رفتار چاپلوسانه را افزایش داده بود که سریعاً بازگردانده شد. از آن زمان، ارزیابیهای اختصاصی برای سنجش تملقگویی توسعه یافته و نمونههای آموزشی جدیدی افزوده شده تا مدل هنگام مواجهه با پرامپتهایی که معمولاً به «موافقت بیش از حد» منجر میشوند، رفتاری متعادل نشان دهد.
در ارزیابیهای هدفمند، نرخ پاسخهای تملقآمیز از 14.5% به کمتر از 6% کاهش یافته است. این بهبودها، ضمن حفظ رضایت کاربر و کیفیت مکالمه، گفتگو را سازندهتر و حرفهایتر میکند؛ دقیقاً همسو با هدف اصلی: کمک به استفاده بهتر از ChatGPT.
شخصیسازی بیشتر ChatGPT برای سبک گفتوگوی شما
GPT‑5 در پیروی از دستورالعملها رشد چشمگیری داشته و همین موضوع پیادهسازی «Custom Instructions» را نیز مؤثرتر کرده است. علاوه بر این، یک پیشنمایش تحقیقاتی از چهار شخصیت ازپیشتعریفشده برای همه کاربران عرضه شده است. این شخصیتها که ابتدا در چت متنی و بعدتر در صدا (Voice) هم ارائه میشوند، اجازه میدهند بدون نوشتن پرامپتهای طولانی، لحن و شیوه تعامل ChatGPT را تنظیم کنید: از حرفهای و موجز گرفته تا حمایتی و متفکر یا کمی طناز و طعنهزن.
چهار گزینه اولیه عبارتاند از: Cynic، Robot، Listener و Nerd. همه اینها اختیاری هستند، هر زمان میتوان آنها را در تنظیمات تغییر داد و برای تطبیق با سبک ارتباطی شما طراحی شدهاند. نکته مهم اینکه هر چهار شخصیت، معیارهای داخلی کاهش تملقگویی را رعایت یا از آن عبور میکنند.
سپرهای چندلایه در برابر ریسکهای زیستی و شیمیایی
OpenAI با در نظر گرفتن تواناییهای GPT‑5 Thinking در حیطه زیستی و شیمیایی، آن را در رده «توانایی بالا» طبقهبندی کرده و سازوکارهای حفاظتی سختگیرانهای را فعال کرده است. بر پایه «چارچوب آمادگی» (Preparedness Framework)، حدود 5000 ساعت Red‑Teaming با شرکایی مثل CAISI و UK AISI انجام شده تا مدل در سناریوهای پرخطر سنجیده شود.
هرچند شواهد قطعی وجود ندارد که این مدل بتواند به یک فرد ناآشنا برای ایجاد آسیب زیستی شدید کمک معناداری کند (آستانه تعریفشده برای توانایی بالا)، OpenAI رویکرد محتاطانهای در پیش گرفته و محافظتها را از همین حالا فعال کرده تا برای آینده آماده باشد. «GPT‑5 Thinking» اکنون یک استک ایمنی قوی با دفاع چندلایه دارد: مدلسازی جامع تهدید، آموزش مدل با پارادایم تکمیل ایمن برای جلوگیری از خروجیهای مضر، طبقهبندها و مانیتورهای استدلال همیشه روشن، و جریانهای اجرایی شفاف برای اعمال سیاستها.
GPT‑5 Pro؛ وقتی پیچیدگی به اوج میرسد
برای وظایف دشوار و چندلایه، نسخه GPT‑5 Pro معرفی شده که جای OpenAI o3‑pro را میگیرد. این مدل با اتکا به محاسبات موازی در زمان اجرا—اما بهینه و مقیاسپذیر—مدت طولانیتری میاندیشد تا کاملترین و باکیفیتترین پاسخها را ارائه کند. در بنچمارکهای هوشی چالشبرانگیز، GPT‑5 Pro بهترین عملکرد را در خانواده GPT‑5 دارد؛ از جمله رکورد جدید روی GPQA که شامل سؤالات علمی بسیار دشوار است.
در ارزیابی بیش از 1000 پرامپت استدلالی مرتبط با کارهای واقعی و ارزش اقتصادی بالا، کارشناسان مستقل در 67.8% موارد GPT‑5 Pro را به «GPT‑5 Thinking» ترجیح دادهاند. همچنین میزان خطاهای عمده 22% کمتر بوده و مدل در سلامت، علوم، ریاضیات و کدنویسی برتری خود را حفظ کرده است. ارزیابان، پاسخهای آن را «مرتبط، مفید و جامع» توصیف کردهاند؛ ویژگیهایی که برای تیمهای متخصص و پروژههای مأموریتحیاتی اهمیت مضاعف دارد.
چطور از GPT‑5 استفاده کنیم؟
GPT‑5 اکنون مدل پیشفرض ChatGPT برای کاربران واردشده (Signed‑in) است و جایگزین GPT‑4o، OpenAI o3، OpenAI o4‑mini، GPT‑4.1 و GPT‑4.5 شده است. کافی است ChatGPT را باز کنید و سؤال خود را تایپ کنید؛ جیپیتی 5 بهصورت خودکار تشخیص میدهد آیا پاسخ به استدلال توسعهیافته نیاز دارد یا خیر. کاربران پولی میتوانند «GPT‑5 Thinking» را از انتخابگر مدل برگزینند یا در متن پرامپت عبارتی مانند «روی این مسئله عمیق فکر کن» بنویسند تا حالت استدلال حتماً فعال شود.
دسترسی و مدلهای اشتراکی
رولاوت GPT‑5 از امروز برای کاربران Plus، Pro، Team و Free آغاز شده و دسترسی برای Enterprise و Edu ظرف یک هفته فعال میشود. مشترکان Pro، Plus و Team همچنین میتوانند با وارد شدن از طریق ChatGPT، کدنویسی با GPT‑5 در Codex CLI را آغاز کنند.
مانند GPT‑4o، تفاوت نسخه رایگان و پولی در «حجم استفاده» است. مشترکان Pro دسترسی نامحدود به GPT‑5 و همچنین دسترسی به GPT‑5 Pro دارند. کاربران Plus میتوانند آن را بهآسودگی بهعنوان مدل پیشفرض برای پرسشهای روزمره بهکار ببرند و سهمیهای بسیار بالاتر از رایگان در اختیار دارند. مشتریان Team، Enterprise و Edu نیز میتوانند از GPT‑5 بهعنوان مدل پیشفرض سازمانی استفاده کنند؛ محدودیتها به اندازهای سخاوتمندانه است که اتکا در سطح تیمها و سازمانهای بزرگ را ممکن میکند. برای کاربران رایگان، فعالسازی کامل تواناییهای استدلالی ممکن است چند روز زمان ببرد. پس از رسیدن به سقف استفاده، آنها به GPT‑5 mini منتقل میشوند—مدلی کوچکتر و سریعتر که همچنان بسیار توانمند است.
سناریوهای کاربردی: از استارتاپ تا سازمان
- توسعه محصول: تیمهای کوچک میتوانند از روی یک طرح دستی یا ماکاپ تصویری، یک لندینگپیج واکنشگرا با طراحی مدرن و تایپوگرافی تمیز تولید کنند. GPT‑5 درک ظریفی از فضاهای خالی و تراز عناصر دارد و میتواند با کمترین اصلاح دستی، یک خروجی آماده استقرار بسازد.
- علم داده و تحلیل: ترکیب توان چندوجهی و استدلال عمیق، خلاصهسازی نمودارها، رفع ابهام در گزارشهای طولانی و استخراج بینش از فایلهای ارائه را ساده میکند. برای مدیران محصول و تحلیلگران کسبوکار، این یعنی چرخه تصمیمگیری سریعتر و با ریسک کمتر.
- پشتیبانی مشتری: پیروی دقیقتر از دستورالعملها و کاهش تملقگویی کمک میکند پاسخها یکدست، مؤدبانه و واقعنما باشند. اگر مسئله مبهم یا انجامناپذیر باشد، GPT‑5 با صداقت حدود و ثغور را توضیح میدهد و راهکار جایگزین پیشنهاد میکند.
- آموزش و یادگیری: از حل تمرینهای ریاضی سطح بالا تا توضیح مفاهیم پیچیده علمی به زبانی ساده، GPT‑5 با توجه به سطح دانش کاربر پاسخ را تنظیم میکند. این انعطاف برای پلتفرمهای Edu و کلاسهای ترکیبی (Hybrid) بسیار ارزشمند است.
- سلامت دیجیتال: بهعنوان یک همراه آگاه، GPT‑5 میتواند نتایج آزمایشها را تفسیر سطحبالا کند، سؤالات درست برای طرح در جلسه پزشک پیشنهاد دهد و منابع قابلاعتماد معرفی کند—همواره با تأکید بر اینکه جایگزین پزشک نیست.
- مهندسی و DevOps: در سناریوهای پیچیده CI/CD، مدل قادر است میان ابزارها هماهنگ عمل کند، لاگها را تحلیل کند، علت ریشهای خطا را بیابد و گامهای اصلاحی را با در نظر گرفتن بهترینعملها پیشنهاد بدهد.
مقایسه با نسلهای قبل و رقبا
- در برابر GPT‑4o: GPT‑5 پاسخهای دقیقتری در دنیای واقعی ارائه میدهد، نرخ خیالپردازی را بهطور قابلتوجهی کم کرده، در چندوجهی و کدنویسی رشد کرده و در لحن، کمتر «ماشینی» و کمتر چاپلوس است. همچنین کارآمدی محاسباتی بالاتری دارد و برای رسیدن به همان یا نتیجه بهتر، توکن کمتری مصرف میکند.
- در برابر OpenAI o3: در حالت Thinking، GPT‑5 با 50 تا 80% توکن خروجی کمتر، عملکرد بهتری ارائه کرده است. نرخ فریبکاری کمتر، پیروی دقیقتر از دستورالعملها و کاهش محسوس خطا در بنچمارکهای حقیقتمحور نیز از برتریهای کلیدی آن است.
- در برابر Agentهای قدیمیتر: در کارهای اقتصادی ارزشمند، GPT‑5 در حدود نیمی از موارد با متخصصان برابری میکند یا بهتر است و نسبت به Agentهای قبلی بازدهی بالاتری دارد. این یعنی سازمانها میتوانند مسئولیتهای بیشتری را بهطور امن به مدل بسپارند.
تأثیر بر آینده کار و سازمانها
GPT‑5 مرزهای بهرهوری را برای تیمهای چندوظیفهای جابجا میکند. از هماهنگی بین ابزارها در جریانهای کاری گرفته تا ایجاد گزارشهای جامع برای مدیریت ارشد، این مدل درک عمیقتری از زمینه، هدف و محدودیتها دارد. با در دسترس بودن شخصیتهای ازپیشتعریفشده و Custom Instructions بهتر، میتوانید مدل را برای فرهنگ سازمانی خودتان تنظیم کنید: حرفهای و موجز برای واحد حقوقی، گفتگوگر و دقیق برای تیم پشتیبانی، یا خلاق و منعطف برای تیمهای مارکتینگ و محصول.
در عین حال، چارچوبهای ایمنی و تکمیل ایمن تضمین میکنند که هرچه اتکا به مدل بیشتر میشود، کنترل و شفافیت نیز افزایش یابد. این ترکیب، بهرهگیری سازمانها از GPT‑5 را هم امنتر و هم اثربخشتر میکند.
جمعبندی: استانداردی تازه برای هوش مصنوعی مولد
GPT‑5 فقط یک ارتقای تدریجی نسبت به نسلهای قبل نیست؛ ترکیبی است از معماری یکپارچه، استدلال توسعهیافته، توان چندوجهی ارتقایافته و ایمنی هوشمندتر که در کنار هم تجربهای یکدست و حرفهای خلق میکنند. از رکوردهای تازه در بنچمارکهای معتبر تا کاهش چشمگیر خیالپردازی و تملقگویی، از صداقت بیشتر در بیان محدودیتها تا شخصیسازی پیشرفته، این مدل بهروشنی نشان میدهد آینده هوش مصنوعی مولد در جهت مفیدتر، مسئولانهتر و نزدیکتر به نیازهای واقعی کاربران و سازمانها حرکت میکند.
اگر کاربر رایگان ChatGPT هستید، طی روزهای آینده بهتدریج مزایای GPT‑5 را تجربه خواهید کرد و پس از رسیدن به سقف استفاده، جیپیتی 5 مینی در کنار شما خواهد بود. اگر مشترک Plus یا Pro هستید، هماکنون میتوانید از این جهش بزرگ بهرهمند شوید و در صورت نیاز، GPT‑5 Pro را برای دشوارترین چالشها انتخاب کنید. برای تیمها و سازمانهایی که بهدنبال اتکای گسترده و پایدار به یک مدل هوش مصنوعی هستند، جیپیتی 5 با محدودیتهای سخاوتمندانه و ابزارهایی مانند Codex CLI آماده است تا تبدیل به موتور محرک نوآوری و بهرهوری شود.